A command-line spreadsheet
The ability to quickly open, explore, summarize, and analyze datasets is an important part of data visualization. As part of putting together data for an infographic on bike thefts in the UK I wanted to see which post codes saw the most reported thefts. Crime data can be downloaded from: data.police.uk.
Sadly it doesn’t include post codes. However, it does provide Lower Layer Super Output Areas (LSOA) which are similar way of dividing up the country into small parcels of land. Looking around we discover the “Postcode to Output Area to Lower Layer Super Output Area to Middle Layer Super Output Area to Local Authority District (December 2011) Lookup in England and Wales” dataset from the Office of National Statistics.
We just need to join the two datasets together! Just as I was reaching for my programming language of choice I remembered an interactive command-line tool called Visidata which I’d wanted to try out on a real data analysis problem.
It sells itself as “great for investigative journalists, data scientists, unix command-line users, and anyone else who wants to quickly look at or manipulate data”. Perfect!
It looks like a familiar spreadsheet.
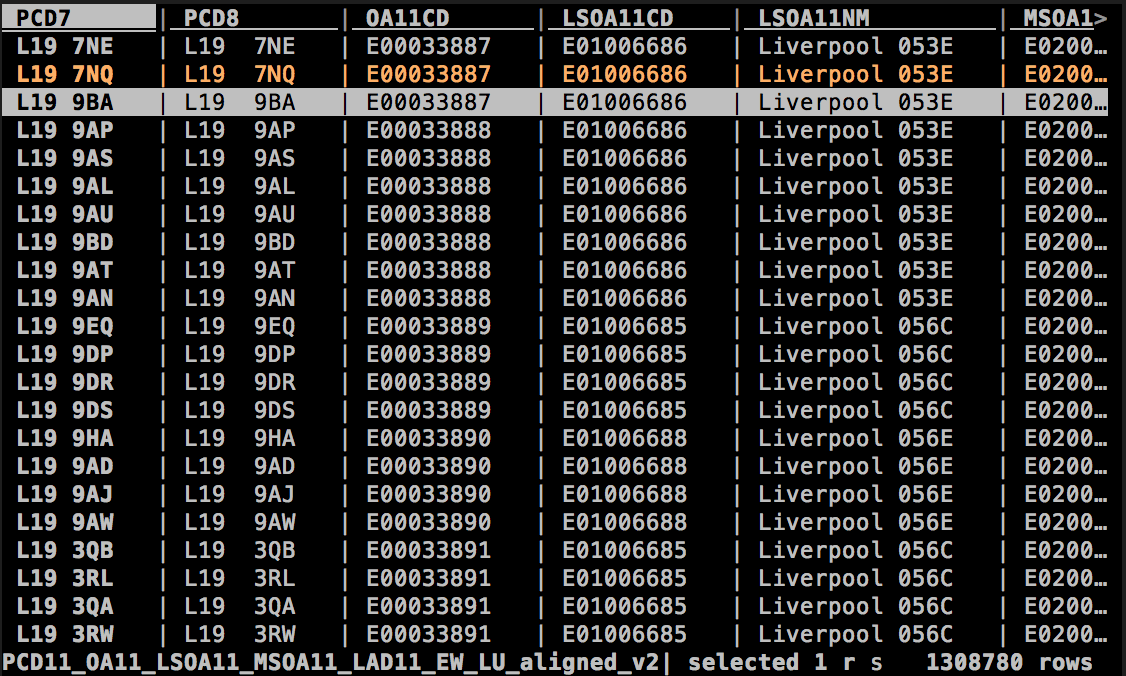
You interact with the data through keyboard shortcuts. It takes a while to learn the basics but once you’re up to speed you really feel productive. I highly recommend An Introduction to VisiData by Jeremy Singer-Vine to get yourself familiar with the tool.
I love the way you can get a quick summary of a dataset by pressing Shift-F to produce a frequency chart.
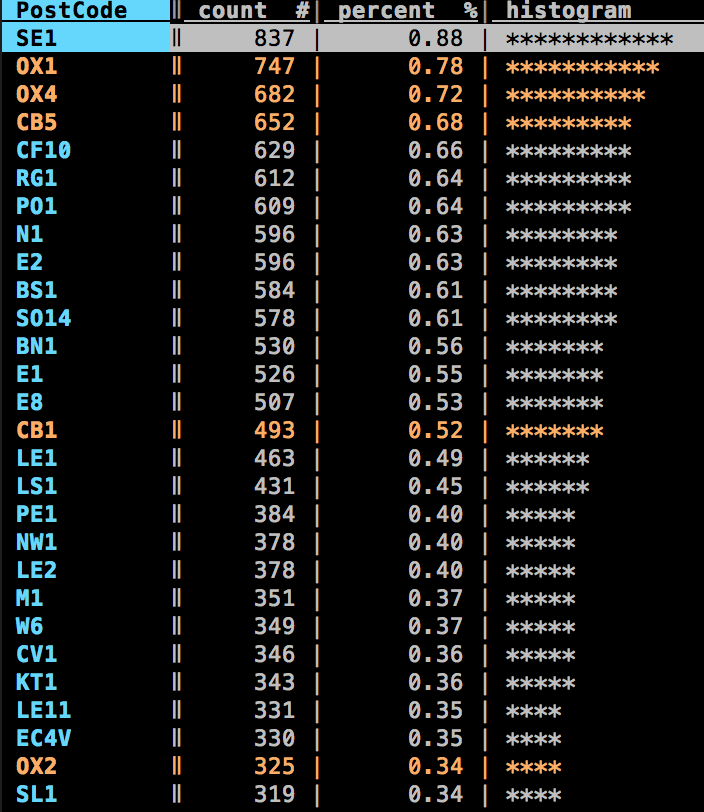
All in all I’ve been impressed by my first experience with Visidata and look forward to using it again.
A couple of issues did crop up. The first was related to the join I wanted to perform. Prior to the join I needed to aggregate the LSOA (location data) column to produce a single row per LSOA value. Visidata doesn’t support this type of operation on text columns as far as I could tell. However, there is a workaround of sorts. The second issue was around performance. One of the files was 1.5GB and operations were taking a while to complete. This isn’t really a criticism as my expectations were that operations on a file this large would take a while anyway. I’m just greedy and will always want my data analysis and transformation to go faster!